En este post os hablaré de otros elementos que son indispensables para las redes neuronales, pero que hasta ahora los habíamos dejado un poco de lado. Quizás os preguntareis porque los hemos dejado de lado. El Deep Learning hay tantísimos elementos que interfieren que hay que priorizar.
Todos estos elementos participan activamente en el proceso de aprendizaje de la red y ayudan que esta converja antes y/o mejor. Si recordamos al inicio en el primer articulo de «Primeras pinceladas», nuestro descenso de gradiente se hacía en un espacio convexo donde se encuentra un mínimo global que es la solución a nuestro problema.
En la realidad, los problemas no son tan sencillos: no son convexos y por lo tanto no tienen un único mínimo global, eso quiere decir que debemos definir estrategias para dotar de cierta robustez al algoritmo y poder adaptarnos de la mejor forma a este tipo de espacios desconocido.
Algo de teoría
En esta parte hablaremos sobre dos conceptos teóricos:
- Los problemas de Overfititng / Underfitting.
- Los conjuntos train, validation, test.
Los problemas de Overfititng / Underfitting
Overfitting y Underfitting son dos problemas que puede estar sufriendo nuestro algoritmo de aprendizaje. Supongamos que tenemos dos conjuntos de datos que queremos separar: rojos y en forma de cruz, y azules y con forma circular.
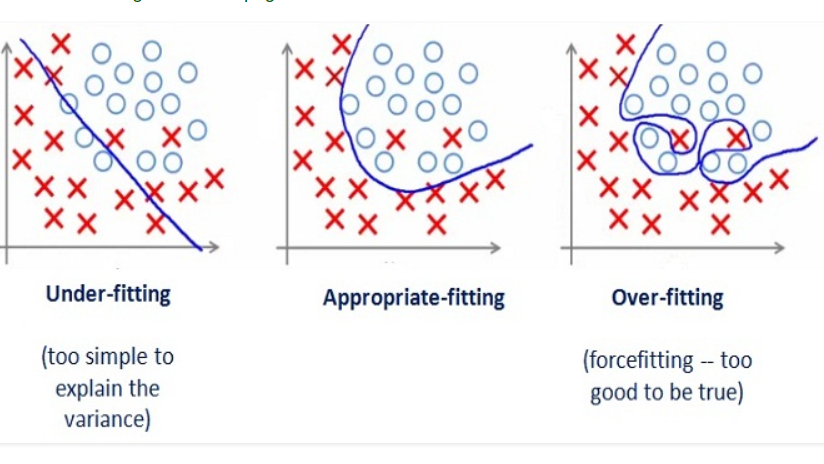
Fuente: https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76
Llamamos Underfitting cuando no los estamos suficiente bien, por lo tanto que nuestro algoritmo es demasiado simple. Decimos que nuestra algoritmo no es suficientemente bueno porque comete demasiado error para el problema que tratamos de resolver.
Llamamos Overfitting cuando nuestro algoritmo los separa demasiado bien. Supongo que os preguntareis ¿Como? ¿Porque demasiado bien es realmente malo? En el aprendizaje computacional siempre aprendemos sobre unas muestras y estas representan nuestra población pero no es una representación perfecta. Estas muestras pueden tener outliers o caracteristicas especificas de esa muestra (valores muy poco comunes que se salen de lo normal), aprender demasiado implica que podriamos estar memorizando estas muestras.
Imaginemos que estamos aprendiendo un algoritmo de detección facial, el overfitting podria suponer solo reconocer caras con las que hemos entrenado. ¿Y es que caras con las que no hemos entrenado, no son caras? Claro que lo son, pero nuestro algoritmo no las reconoce como tal y por ende nuestro algoritmo puede estar tendiendo a memorizar muestras.
Otro claro ejempo de overfitting es entrenar un detector de coches solamente con coches rojos, ¿Os imaginais que va a pasar?
Conjuntos de training, validation y test:
Cuando se nos presenta un problema de aprendizaje computacional normalmente el conjunto total de datos se separan en estos tres conjuntos:
- training: usaremos estos datos únicamente para entrenar nuestro algoritmo. Debemos tener los datos etiquetados.
- validation: usaremos estos datos para validar si está aprendiendo correctamente nuestro algoritmo. Debemos tener los datos etiquetados.
- test: usaremos estos datos para probar nuestro algoritmo.
Separar nuestros datos en estos tres conjuntos nos permite saber como realmente esta aprendiendo nuestro algoritmo. Centrémonos son los dos primeros (los más importantes) que participan activamente en el aprendizaje.
Lo que vamos a explicar se llama el problema del bias/variance tradeoff. Veamos el siguiente gráfico:
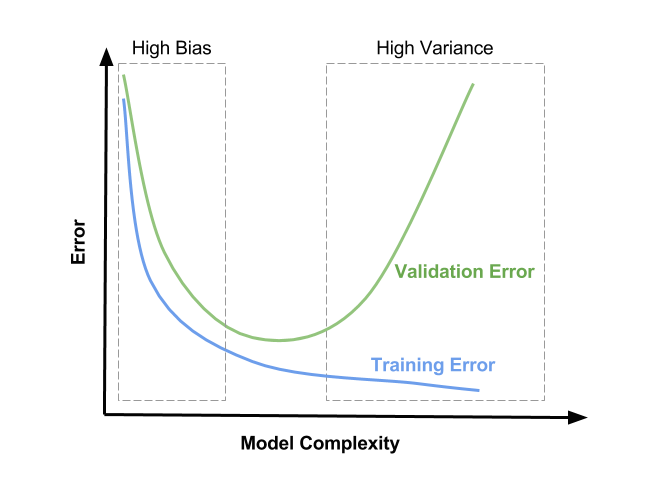
Fuente: https://www.learnopencv.com/bias-variance-tradeoff-in-machine-learning/
Este gráfico representa nuestro algoritmo como va aprendiendo respecto al tiempo.
- High Bias: se refiere a cuando nuestro algoritmo aún tiene un error muy elevado en ambos conjuntos. Estamos en underfitting.
- High Variance: se refiere a cuando hay una diferencia considerable entre el error de training con el de validación. Estamos empezando a memorizar las muestras y estamos en overfitting.
Optimizador
El optimizador es el encargado de: obtener la derivada respecto a un peso y corregirlo, el cómo lo haga es cosa suya.
w = optimizador_{\sigma}(\frac{\partial J}{\partial w}) donde w son los pesos a corregir y \sigma los hyperparametros del optimizador.
Hyperparámetros:
Existen diversos parámetros que comparten distintos optimizadores que nos pueden ayudar a un mejor aprendizaje de nuestra red.
Learning Rate
El learing rate es un parámetro común en prácticamente todos los optimizadores (aunque algunos lo estiman). Si nos basamos en un descenso de gradiente puro y duro (vanilla gradient descent), el learning rate es el que indica que intervalo de tiempo se ha producido y como consecuencia el avance entre los intervalos de w.
\frac{\partial W}{\partial t} = \frac{w_{t+1} - w_{t}}{\underbrace{lr}_{\text{tiempo transcurrido entre [latex]w_{t+1} y w_{t}}}} = - \frac{\partial J}{\partial w}[/latex]
w_{t+1} = w_{t} - lr \frac{\partial J}{\partial w}
Escoger un mal lr, puede ser desastroso para nuestra red. Tal y como explicamos en el primer articulo:
- Un lr muy pequeño va a tarda mucho en avanzar hasta llegar a la solución. Esto puede hacer que como nuestro tiempo de entrenamiento es limitado, cuando cortemos el aprendizaje aun estemos descendiendo.
- Un lr muy alto, a consecuencia de discretizar el tiempo, tomaremos una aproximación de la dirección que nos lleva al mínimo. ¿Pero y si este salto es demasiado elevado y pasamos por encima el mínimo? ¿Y si este salto pasa por encima un estado que seria la clave para encontrar el mínimo absoluto?

Fuente original: https://www.jeremyjordan.me/nn-learning-rate/
Normalmente el learning rate adecuado comprende valores de entre 10^-2 a 10^-5.
Un mal learning rate se puede tambien «sospechar» en las curvas de aprendizaje (concretamente la de training):

Fuente: https://www.hackerearth.com/blog/machine-learning/3-types-gradient-descent-algorithms-small-large-data-sets/
Momentum
El momentum es un elemento muy útil que nos permite coger «velocidad mientras descendemos» para ser capaces de saltarnos pequeños mínimos locales que puede haber en espacio y reducir el ruido por batch o muestra del gradiente actual. Veamos la siguiente animación para entender el concepto (es puramente ilustrativa):
GD sin momentum
|
GD con momentum
|


En resumidas cuentas, el momentum queda expresado de la siguiente forma:
\Delta_{w_{t+1}} = - lr \frac{\partial J}{\partial w} + \mu \Delta_{w_{t}}
w_{t+1} = w_{t} + \Delta w_{t+1}
Como veis esta vez el peso w no se actualiza directamente con la dirección actual sino que es la ponderación con la dirección acumulada (\Delta w_{t} y donde \mu es el parámetro que pondera la mezcla).
También ofrece algo más de robustez frente a batches o muestras que no representan nuestra población y hacen que el algoritmo tienda a ir en otra dirección (por ejemplo si entrenamos un reconocedor de dígitos, que cojamos un batch con solo 1’s).
Learning Rate Decay
A medida que se desciende en el descenso de gradiente seria interesante poder ir haciendo pequeño el learning rate con el fin de que cada vez vaya disminuyendo el avance. Esto es lo que define exactamente la política de Learning Rate Decay, esta se va a encargar de ir disminuyendo. Una política usada es la siguiente:
lr = lr_{\text{inicial}} \frac{1}{1 + \text{decay} \cdot \text{iteraciones}}, donde decay es el parámetro que indica la velocidad de decrecimiento a medida que pasan las iteraciones.
Gradient Clipping
Las redes neuronales habitualmente tienen problemas de gradient explosion, el gradiente se hace muy muy grande, aparecen NaNs por ahí y todo se va la m*?#!.
Fuente: Hinton’s Coursera Lecture Videos.
La finalidad del gradient clipping es cortar aquellos gradientes que tienen un valor muy elevado, existen dos formas de aplicar gradient clipping:
- clip value: recorta los valores que superan un umbral.
\nabla w_{t} = max(-clip, min(clip, \nabla w_{t})) - clip norm: rescala los valores que su magnitud supera un umbral.
\nabla w_{t} = \frac{clip}{max(clip, ||\nabla w_{t}||)}\nabla w_{t}
Algoritmos:
Existen distintos algoritmos que nos permiten encontrar corregir los parámetros de nuestra red, en este articulo os enseñaré algunos de ellos.
Si queréis acabar de ver otros y su funcionamiento os recomiendo ir a http://caffe.berkeleyvision.org/tutorial/solver.html.
Schocastic Gradient Descend
El primero de todos estos algoritmos es el más sencillo. En SGD, nos desplazamos usando únicamente una muestra del dataset. Acostumbra a ser un descenso de gradiente muy turbulento porque todas las pequeñas variaciones en las muestras van a provocar ruido.
Al contrario de lo que puede parecer a simple vista, este tipo de enfoque a veces es practico para explorar espacios de soluciones que de lo contrario nunca llegaríamos.
\frac{\partial J}{\partial w} = \frac{\partial Loss(x^i, y^i)}{\partial w}
En aspectos prácticos es lo mismo que usar un Batch Gradient Descend con un tamaño de 1.
Batch Gradient Descend (Gradient Descend o Vanilla Gradient Descend)
Usamos BGD para minimizar el ruido/muestra y maximizar la representación del gradiente respecto la población (todo el dataset). Usaremos N muestras para representar la dirección del gradiente de \frac{\partial J}{\partial W}.
\frac{\partial J}{\partial w} = \frac{1}{N} \sum_i^N \frac{\partial Loss(x^i, y^i)}{\partial w}
Gradient Descend acelerado por Nesterov
Un día ojeando Keras me di cuenta de que dentro de el optimizador SGD había una variable llamada Nesterov, la verdad en ese momento no entendí muy bien para que servia así que decidí informarme. Pues bien esa variable activaba la aceleración de gradiente propuesta por Nesterov la cual es muy interesante.
Cuando se usa el descenso de gradiente convencional usamos el estado actual de los pesos para determinar la dirección, Nesterov propone otro tipo de aproximación:
- Estimaremos directamente la siguiente posición usando la dirección acumulada (similar a lo que ofrecia el momentum) \color{brown} \text{estimacion} \color{black} =\color{brown} \mu \Delta_{w_{t}}.
- Vamos a corregir la estimación buscando la dirección del estado actual + direccion acumulada, \color{red} \text{correccion} \color{black} = \color{red} - lr \cdot \frac{\partial J}{\partial w} (w_t + \mu \Delta_{w_{t}}).
- Uniremos ambos conceptos: \color{green} \Delta_{w_{t+1}}\color{black} = \color{brown} \text{estimacion} \color{black} + \color{red} \text{correccion}, quedando de la siguiente forma:
\color{green} \Delta_{w_{t+1}} \color{black} =\color{brown} \mu \Delta_{w_{t}} \color{red} - lr \frac{\partial J}{\partial w} (w_t + \mu \Delta_{w_{t}}) - Aplicaremos otra vez los anteriores pasos, dando como resultado:
w_{t+1} = w_t + \mu \Delta_{w_{t+1}} - lr \cdot \frac{\partial J}{\partial w} (w_t+ \mu \Delta_{w_{t}})

Fuente: https://www.youtube.com/watch?v=8yg2mRJx-z4
Pero aplicar Nesterov directamente supone el problema de tener que evaluar el valor de la derivada en la estimación, lo que acaba suponiendo más cálculos. El articulo «ADVANCES IN OPTIMIZING RECURRENT NETWORKS», realiza una simplificación de este método:
\color{green} \Delta_{w_{t+1}} \color{black} =\color{brown} \mu \Delta_{w_{t}} \color{black} - lr \frac{\partial J}{\partial w} (w_t)
w_{t+1} = w_t + \mu \Delta_{w_{t+1}} - lr \cdot \frac{\partial J}{\partial w} (w_t)
AdaGrad
AdaGrad es un algoritmo propuesto por John Duchi en el que como su nombre indica es un Adaptative Gradient.
Este algoritmo es el primer método de gradiente adaptativo, este concepto se basa en estimar un adecuado learning rate para los pesos usando el gradiente de los mismos pesos. El algoritmo analizará que cambios se producen en el gradiente durante el tiempo para:
- Aumentar el learning rate para aquellos pesos que se actualizan puntualmente.
- Disminuir el learning rate para aquellos pesos que se actualizan constantemente.
Es un algoritmo ampliamente usado en la industria y que además incluye un proceso de learning rate decay a lo largo del aprendizaje. Digamos que es un… ¡2×1! ¡BRILLANTE!
g^2_{t} = g^2_{t-1} + \frac{\partial J}{\partial w}^2
w_{t+1} = w_{t} - \frac{\mu}{\sqrt{g^2_{t} + \epsilon}} \frac{\partial J}{\partial w}
AdaDelta
El algoritmo AdaDelta es una mejora del AdaGrad en el que se relaja la condición de g^2_{t} = g^2_{t-1} + \frac{\partial J}{\partial w}^2, puesto que esta puede crecer demasiado rápido y no tenemos un control sobre dicho crecimiento.
E \left [\frac{\partial J}{\partial w}^2 \right ]_{t} = \gamma E \left [\frac{\partial J}{\partial w}^2 \right ]_{t-1} + (1 -\gamma) \frac{\partial J}{\partial w}^2
\Delta_{w_{t}} = - \frac{\mu}{\underbrace{\sqrt{E \left [\frac{\partial J}{\partial w}^2 \right ]_{t} + \epsilon}}_{RMS \left [\frac{\partial J}{\partial w} \right ]_t}} \frac{\partial J}{\partial w}
Donde \sqrt{E \left [\frac{\partial J}{\partial w}^2 \right ]_{t} + \epsilon} también se conoce como root mean square de \frac{\partial J}{\partial w} que equivale a RMS \left [\frac{\partial J}{\partial w} \right ]_t.
Además substituye \mu por una aproximación de la misma naturaleza RMS[\Delta_{w}]_{t-1} (Se usa t-1 porque se desconoce el valor que puede tener RMS[ \Delta_{w} ]_{t} ya que aún no se ha calculado \Delta_{w_{t}}). Quedando de la siguiente forma:
RMSProp
Es una alternativa basada en AdaGrad que se propuso en un curso de Coursera por Geoff Hinton. En esencia hace lo mismo que AdaDelta pero sin complicarlo tanto, se trata de tener un mejor control sobre g^2_{t} y relajar su crecimiento.
E[g^2_{t}] = 0.9 E[g^2_{t-1}] + 0.1 \frac{\partial J}{\partial w}^2
w_{t+1} = w_{t} - \frac{\mu}{\sqrt{g^2_{t} + \epsilon}} \frac{\partial J}{\partial w}
Adam
Adam es un método similar al que usábamos en el momentum (se le llama coloquialmente un RMSProp con momentum).
m_0 = 0, v_0 = 0
m_t = \beta_1 m_{t-1} + (1 - \beta_1)\frac{\partial J}{\partial w}
v_t = \beta_2 v_{t-1} + (1 - \beta_2)\frac{\partial J}{\partial w}^2
Pero a diferencia de los métodos anteriores. El articulo de este optimizador (ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION), se explica que los creadores observaron que en etapas muy tempranas ambas variables tanto m_t y v_t tendían a tener valores cercanos a 0, eso se debía a que al inicio las inicializaban a 0. Para contrarrestar este factor se usa la siguiente corrección:
\hat{m}_t = \frac{m_t}{1 - \beta_1^t}
\hat{v}_t = \frac{v_t}{1 - \beta_2^t}
Y finalmente se actualizan los parámetros:
w_{t+1} = w_{t} - \mu \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}
Inicialización de los pesos
Si hay algo que no se toma muy enserio cuando se llega por primera vez al Deep Learning estos son las inicializacion de los pesos. Recordemos que cuando ponemos por primera vez en marcha nuestra red neural a esta se le deben poner unos valores iniciales en todos sus pesos (normalmente aleatorios). Estos valores deben cumplir ciertas consideraciones que harán que funcionen mucho mejor:
- Deben evitar problemas de gradient exploding y vanish gradient. Ni podemos inicializar con valores a 0, ni podemos inicializar con valores de magnitud muy grande.
- Deben haber tener valores distintos, sino lo que sucedería es que estaremos representando exactamente lo mismo en dos pesos distintos.
En este apartado como en los otros, no hay ninguna ciencia cierta sobre como inicializarlos, pero si podemos aplicar cierta intuición.
Lecun
La inicialización de Lecun parte de una premisa muy inteligente, recordemos que prácticamente todos los pesos funcionan del mismo modo: se multiplican por la entrada y se suman.
y = W^T x
Nuestra misión es tratar de preservar el rango [-1, 1]. Si x ya comprende valores de [-1, 1] ¿Que valores deberá tener W para que y siga en ese rango? Para ello analicemos un momento la operación entre W y x:
W^T x = W_0 x_0 + W_1 x_1 + ... + W_n x_n
Una solución para preservar el rango seria decir que W_t = \frac{1}{n}, pero obviamente no podemos inicializar todos los pesos igual… Así que porque no representamos la misma condición usando la varianza de W:
Var(W) = \frac{1}{n}
Ahora estamos diciendo que los pesos de W deben seguir una distribución normal de N\left (0, \sqrt{\frac{1}{n}} \right ) o \text{unif} \left ( - \sqrt{\frac{1}{n}} , \sqrt{\frac{1}{n}}\right ).
Otro aspecto interesante que se implementa es truncar esta distribución normal por valores superiores a 2 e inferiores a – 2. ¿Porque? Para evitar problemas de vanish gradient en la capa de activación. Después de una capa de pesos normalmente viene otra de activación (función no lineal). Veamos la función sigmoide y la función tanh:
|
|
 |

Como podéis ver estas funciones empiezan a homogeneizar los valores superiores a 2 e inferiores a -2. Eso quiere decir que un valor superior a 2 o inferior a -2 tendrá muy pocas posibilidades de actualizarse correctamente y probablemente acabe muriendo su gradiente.
Xavier / Glorot
Es un planteamiento muy similar al anterior pero en este caso se contempla tanto la entrada como la salida (realiza la media armónica de ambas):
N\left (0, \sqrt{\frac{2}{n_{in} + n_{out}}} \right ) \text{ o }\text{unif}\left (-\sqrt{\frac{2}{n_{in} + n_{out}}}, \sqrt{\frac{2}{n_{in} + n_{out}}}\right )
He
Es una inicialización que ayuda la convergencia de capas que vienen precedidas de una activación ReLU. Es bastante similar a Lecun, podeís verlo ver todo el desarrollo en el articulo completo: Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.
N\left (0, \sqrt{\frac{2}{n}} \right ) \text{ o } \text{unif} \left ( - \sqrt{\frac{2}{n}} , \sqrt{\frac{2}{n}}\right )
Regularizadores:
Los regularizadores son útiles cuando nuestra red tiene problemas de overfitting, eso nos está indicando que está esta aprendiendo demasiado sobre el conjunto de entrenamiento.
El concepto de regularizador es asociar que el problema de overfitting viene ligado con la variabilidad de los pesos que tiene la red, es decir: Si un peso w tiene muchos grados de libertad es posible que represente demasiado bien el conjunto de training y la red tenga overfitting. La solución es forzar el peso a tener un orden de magnitud mas pequeño o incluso cero (pesos muertos).
Al final hace que el peso tenga que buscar un compromiso entre minimizar la loss function sin ser extremadamente complejo.
error = \sum_i L(x^i, y^i) + \sum_k \text{regularizador}(w_k)
Existen dos regularizaciones que se usan habitualmente:
- L1: \text{regularizador}(w_k) = \lambda |w_k|
- L2: \text{regularizador}(w_k) = \lambda ||w_k||^2
Para entender el funcionamiento partiremos del siguiente gráfico y definiremos \lambda = 1.

Este gráfico representa la curva de nivel en dos dimensiones tanto de L1 como de L2 cuando la regularización vale 1. Eso quiere decir que:
- |w_0| + |w_1| = 1
- ||w_0||^2 +||w_1||^2 = 1
Y dibujamos todos los valores de <span style="color: #33cccc;">w_0 y w_1 que cumplen esta condición para L1 y para L2.
Sparse/ No sparse
Ahora tendemos que hacer un pequeño ejercicio de imaginación. Supongamos que existe una linea que son todas las posibles soluciones a nuestro problema de aprendizaje (linea azul) y posibles penalizaciones en L1 y en L2 (linea cian). Ademas esta linea pasa justamente por donde la regularización da 1.

Para continuar deberemos derivar ambos casos:
- L1: \frac{\partial L1}{\partial w_k} = \lambda sign(w_k), donde sign es la función signo.
- L2:\frac{\partial L1}{\partial w_k} = \frac{\lambda}{2} w_k
En cambio en L2 la derivada si depende de la magnitud, por lo tanto a medida que el peso disminuye tambien lo hace su corrección, costando mucho muchisimo más que este llegue a cero (realmente infinito).
Por lo tanto L1 es mucho más propenso a generar soluciones sparse que L2. De hecho las esquinas de L1 son las soluciones sparse al problema.
Unica solucion / Multiples soluciones
Si suponemos otro ejercicio de imaginacion similar y proponemos otra linea de posibles soluciones (linea azul) que pasa justamente por uno de los lados de L1 y L2. Nos encontraremos lo siguiente:
Como podeis observar en L1 existe más de una intersección con la solución, por lo tanto tenemos multiples soluciones. En cambio en L2, solo tenemos una interección y por lo tanto tenemos una unica solución.
Veamos las conclusiones que podemos sacar:
| L1 | L2 |
|---|---|
| Multiples soluciones. | Una unica solución. |
| Podemos observar que no importa el valor que tenga el peso sino que mientras sea superior o inferior a cero siempre será penalizado por igual (\lambda). | Penalizará los pesos acorde a su magnitud. |
| Solo cogerá los pesos que aportan realmente valor a la solución, los demás acabarán valiendo 0 (feature selection). | Los cogerá todos. |
| La solución que dará L1 siempre será sparse. | No asegura que la solución sea sparse, es una solución smooth. |
Extra
Para que veais que no solamente existen L1 y L2 (aunque son las que más se usan) vamos a usar la p-norm de Minkowski, esta distancia permite unificar todo un conjunto: L-0, L-1, L-2, …, L-infinito.
L \text{-p} = \sqrt[\frac{1}{p}]{\sum_i |w|^{p}}

Algunos de estos conceptos actualmente ya estan implementados en Network from Scratch.
¡Y esto ha sido todo espero que te haya gustado! Nos vemos en proximos posts 😉
Referencias:
- Una gran explicación técnica sobre los algoritmos de optimización, en donde me he basado para explicar algunos de ellos. http://ruder.io/optimizing-gradient-descent/
- https://hackernoon.com/gradient-clipping-57f04f0adae
- https://arxiv.org/pdf/1212.0901v2.pdf
- https://stats.stackexchange.com/questions/179915/whats-the-difference-between-momentum-based-gradient-descent-and-nesterovs-acc
- http://caffe.berkeleyvision.org/tutorial/solver.html
- https://intoli.com/blog/neural-network-initialization/
- https://revisionmaths.com/advanced-level-maths-revision/statistics/uniform-distribution
- https://es.wikipedia.org/wiki/Geometr%C3%ADa_del_taxista
- https://en.wikipedia.org/wiki/Lp_space#The_p-norm_in_finite_dimensions


